
渲染优化
浏览器从获取 HTML 到最终在屏幕上显示内容需要完成以下步骤:
- 处理 HTML 标记并构建 DOM 树;
- 处理 CSS 标记并构建 CSSOM 树;
- 将 DOM 与 CSSOM 合并成 render Tree;
- 根据渲染树来布局,以计算每个节点的几何信息;
- 将各个节点绘制到屏幕上。
经过上述流程我们才可以看到屏幕上出现渲染的内容,所以我们需要优化关键渲染路径。
它指的是最大限度地缩短执行上述第 1 步至第 5 步耗费的总时间,让用户最快的看到首次渲染的内容。
不但网站页面要快速加载出来,而且运行也要流程,在响应用户操作时也要更加及时。那么要达到怎样的性能指标,才能满足用户流程的使用体验?
目前大部分设备的屏幕分辨率都在 60 fps 左右,即每秒屏幕会刷新 60 次,所以要满足用户的体验期望,就需要浏览器在渲染页面动画或响应用户操作时,每一帧的生成速率尽量接近屏幕的刷新率。按照 60 fps 来算,留给每一帧画面的时间不超过 17 ms,除去浏览器对资源的一些整理工作,一帧画面的渲染应该尽量在 10ms 内完成,如果达不到要求导致帧率下降,屏幕上的内容就会发生抖动或者卡顿。
为了让每一帧页面渲染的开销都能在期望的时间范围内完成,就需要开发者了解渲染过程的每个阶段,以及各个阶段有哪些优化空间。
根据开发者对优化渲染过程中控制力度,可以大体将其划分为五个部分:JavaScript 处理、计算样式、页面布局、绘制和合成。
关于更多浏览器的渲染流程知识,可以查看这篇文章 - 现代浏览器渲染流程。
- JavaScript 处理:前端项目中经常会响应用户操作,通过 JavaScript 对数据集进行计算、操作 DOM 元素,并展示动画等视觉效果。对于动画的实现,除了 JavaScript,也可以考虑使用如 CSS Animations、Transitions 等技术。
- 计算样式:解析 CSS 文件后,浏览器需要根据各种选择器去匹配所要应用 CSS 规则的元素节点,然后计算出每个元素的最终样式。
- 页面布局:指的是浏览器在计算完成样式后,会对每个元素尺寸大小和屏幕位置进行计算。由于每个元素都可能会受到其他元素的影响,并且位于 DOM 树形结构中的子节点元素,总会受到父级元素修改的影响,所以页面布局的计算会经常发生。
- 绘制:在页面布局确定后,接下来便可以绘制元素的可视内容,包括颜色、边框、阴影及文本和图像。
- 合成:通常由于页面中的不同部分可能被绘制在多个图层中,所以在绘制完成后需要将多个图层按照正确地顺序在屏幕上合成,以便最终正确地渲染出来。
这个过程中的每一阶段都有可能产生卡顿。这里需要说明的是,并非对于每一帧画面都会经历这五个部分。比如仅修改与绘制相关的属性(文字颜色、背景图片或阴影等),而未对页面布局产生任何修改,那么在计算样式阶段完成之后,会跳过页面布局直接执行绘制。
关键渲染路径优化
关键渲染路径指的就是从 HTML 到屏幕内容展示所经历的整个过程,我们需要让用户尽快地看到首次渲染内容。
为了尽快完成首次渲染,我们需要最大限度地减少以下三种可变因素:
- 关键资源数量
- 关键路径长度
- 关键字节数量
关键资源指的是可能阻止网页首次渲染的资源。例如 JavaScript、CSS 都是可以阻塞关键渲染路径的资源,这些资源越少,浏览器的工作量就越小,对 CPU 以及其他资源的占用也就越少。
关键路径长度受所有关键资源与其字节大小之间依赖关系图的影响:某些资源只能在上一资源处理完毕后才能开始下载,并且资源越大,下载所需的往返次数就越多。
浏览器需要下载的关键字节越少,处理内容并让其出现在屏幕上的速度就越快。要减少字节数,我们可以减少资源数(将它们删除或设为非关键资源),此外还要压缩和优化各项资源,确保最大限度地减少传送大小。
优化 DOM
在关键渲染路径中,构建渲染树(Renderer Tree)的第一步就是构建 DOM,所以我们先讨论如何让构建 DOM 的速度变得更快。
HTML 文件的内容应该尽可能的小,目的是为了让客户端尽可能早的接收到完整的 HTML。通常 HTML 中有很多冗余的字符,例如:JS 注释、CSS 注释、HTML 注释、空格、换行。更糟糕的情况是生产环境中的 HTML 里面包含很多废弃代码,这可能是由于时间的推移,项目越来越大,由于种种原因从历史遗留下来的问题,不过不管怎么说,这都是很糟糕的。对于生产环境的 HTML 来说,应该删除一切无用的代码,尽可能保持 HTML 文件精简。
有三种方式可以优化 HTML:缩小文件尺寸(Minify)、使用 gzip 压缩、使用缓存(HTTP Cache)。
缩小文件尺寸(Minify)会删除注释、空格与换行等无用的文本。
本质上,优化 DOM 其实是在尽可能的减少关键路径的长度与关键字节的数量。
优化 CSSOM
CSS 是构建渲染树的必备元素,首次构建网页时,JavaScript 常常受阻于 css。确保将任何非必须的 CSS 都标记为非关键资源,应确保尽可能减少关键 CSS 的数量,以及尽可能缩短传送时间。
阻塞渲染的 CSS
CSS 还有一个可以影响性能的因素是:CSS 会阻塞关键渲染路径。
CSS 是关键资源,它会阻塞关键渲染路径并不奇怪,但并不是所有的 CSS 资源都很关键。
例如一些响应式 CSS 只在屏幕宽度符合条件时才会生效,还有一些 CSS 只在打印页面时才会生效。这些 CSS 在不符合条件时,是不会生效的,所以我们不需要让浏览器等待这些资源。
针对这种情况,我们应该让这些非关键字的 CSS 资源不阻塞渲染。
<link href="style.css" rel="stylesheet">
<link href="print.css" rel="stylesheet" media="print">
<link href="other.css" rel="stylesheet" media="(min-width: 40em)">
<link href="portrait.css" rel="stylesheet" media="orientation:portrait">
- 第一个声明阻塞渲染,适用于所有情况;
- 第二个声明只在打印网页时应用,因此网页首次在浏览器加载时,不会阻塞渲染;
- 第三个声明提供由浏览器执行的 “媒体查询”:符合条件时,浏览器将阻塞渲染,直至样式表下载完毕;
- 最后一个声明是动态媒体查询,将在网页加载时计算。根据网页加载时设备的方向进行加载。
“阻塞渲染” 仅指浏览器是否需要暂停网页的首次渲染,直至该资源准备就绪。无论哪一种情况,浏览器仍会下载 CSS,只不过不阻塞渲染的 CSS 资源优先级比较低。
为了获得最佳性能,还可以考虑将关键 CSS 直接内联到 HTML 文档内。这样做不会增加关键路径中的往返次数,并且如果使用得当,在只有 HTML 是阻塞渲染的资源时,可以实现 “一次往返” 关键路径长度。
避免使用 @import
我们应该都知道要避免使用 @import 加载 css,实际工作中我们也不建议这样去加载 css,这是因为使用 @import 加载 CSS 会增加额外的关键路径长度。
<!doctype html>
<html>
<head>
<meta charset="UTF-8">
<title>Demos</title>
<link rel="stylesheet" href="http://127.0.0.1:8887/style.css">
<link rel="stylesheet" href="https://lib.baomitu.com/CSS-Mint/2.0.6/css-mint.min.css">
</head>
<body>
<div class="cm-alert">Default alert</div>
</body>
</html>
这段代码使用 link 标签加载了两个 CSS 资源,这两个资源是并行下载的。如果我们使用 @import 加载资源:
/* style.css */
@import url('https://lib.baomitu.com/CSS-Mint/2.0.6/css-mint.min.css');
body{background:red;}
<!doctype html>
<html>
<head>
<meta charset="UTF-8">
<title>Demos</title>
<link rel="stylesheet" href="http://127.0.0.1:8887/style.css">
</head>
<body>
<div class="cm-alert">Default alert</div>
</body>
</html>
代码中使用 link 标签加载一个 CSS,然后在 CSS 文件中使用 @import 加载另一个 CSS。
可以看到两个 CSS 变成串行加载,前一个 CSS 加载完成后再去下载使用 @import 导入的 CSS 资源。这会导致加载资源的总时间变长。
所以我们要避免使用 @import 引入 CSS 样式,可以降低关键路径的长度。
优化 JavaScript
使用 defer 延迟加载
与 CSS 资源相似,JavaScript 资源也是关键资源,JavaScript 资源会阻塞 DOM 的构建,并且 JavaScript 会被 CSS 文件所阻塞。
当浏览器加载 HTML 时遇到 <script>xxx</script> 标签,浏览器就不能继续构建 DOM。它必须立即执行此脚本。对于外部脚本 <script src=""></script> 也是一样的,浏览器必须等脚本下载完,并执行结束,才能继续处理剩余的页面。
这会导致两个问题:
- 脚本不能访问到位于它们下面的 DOM 元素,因此,脚本也无法给它们添加处理程序;
- 如果页面顶部有一个很大的脚本,它会 “阻塞页面”。在该脚本下载并执行结束前,用户都不能看到页面内容。
<p>...content before script...</p>
<script src="https://javascript.info/article/script-async-defer/long.js?speed=1"></script>
<!-- This isn't visible until the script loads -->
<p>...content after script...</p>
我们可以把脚本放到页面底部。此时,它可以访问上面的元素,并且不会阻塞页面内容显示。
<body>
...all content is above the script...
<script src="https://javascript.info/article/script-async-defer/long.js?speed=1"></script>
</body>
但是这种解决方法并不完美。例如,浏览器只有在下载了完整的 HTML 文档之后才会下载该脚本。对于长的 HTML 文档来说,可能会造成明显的延迟。有两个 <script> 特性(attribute)可以为我们解决这个问题:defer 和 async。
defer 特性告诉浏览器不要等待脚本。浏览器会继续处理 HTML,构建 DOM,脚本会在 “后台” 下载,等 DOM 构建完成后,脚本才会执行。下面是与上面相同的示例,不过带有 defer 特性:
<p>...content before script...</p>
<script defer src="https://javascript.info/article/script-async-defer/long.js?speed=1"></script>
<!-- 立即可见 -->
<p>...content after script...</p>
- 具有 defer 特性的脚本不会阻塞页面;
- 具有 defer 特性的脚本总是会等到 DOM 解析完毕,在
DOMContentLoaded时间之前执行。
下面这个示例可以验证上面第二句话。
<p>...content before scripts...</p>
<script>
document.addEventListener('DOMContentLoaded', () => alert("DOM ready after defer!"));
</script>
<script defer src="https://javascript.info/article/script-async-defer/long.js?speed=1"></script>
<p>...content after scripts...</p>
- 页面内容立即展示;
DOMContentLoaded事件处理程序等待具有defer特性的脚本执行完成。仅在脚本下载并执行结束后才会被触发。
具有 defer 特性的脚本保持其相对顺序,与常规脚本一致。
假设,我们有两个具有 defer 特性的脚本:long.js 在前,small.js 在后。
<script defer src="https://javascript.info/article/script-async-defer/long.js"></script>
<script defer src="https://javascript.info/article/script-async-defer/small.js"></script>
浏览器扫描页面寻找脚本,然后并行下载它们,以提高性能。因此,在上面的示例中,两个脚本是并行下载的。
small.js 可能会先下载完成,但是 defer 特性除了会告诉浏览器不要 “阻塞页面” 之外,还可以确保脚本的相对执行顺序。因此,即使 small.js 先加载完成,也需要等到 long.js 执行结束后才会被执行。
当我们需要先加载 javascript 库,然后再加载依赖于它的脚本时,这可能会很有用。
注意:defer 特性仅作用于外部脚本,如果
<script>脚本没有src,则会忽略defer特性。
使用 async 延迟加载
async 特性与 defer 类似。它也能够让脚本不阻塞页面,但是在行为上两者有重要的区别。
async 特性意味着脚本是完全独立的:
- 浏览器不会因 async 脚本而阻塞。
- 其他脚本不会等待 async 脚本加载完成,同样,async 脚本也不会等待其他脚本。
DOMContentLoaded和异步脚本不会彼此等待:DOMContentLoaded可能会发生在异步脚本之前(如果异步脚本在页面完成后才加载成功);DOMContentLoaded也可能发生在异步脚本之后(如果异步脚本很短,或者从 HTTP 缓存中加载)。
async 脚本会在后台加载,并在加载完毕后立即执行。DOM 和其他脚本不会等待它们,它们也不会等待其他内容。async 脚本就是一个在加载完成时执行的完全独立的脚本。
下面也有一个例子,和上面的例子类似。同样存在 long.js 和 small.js 两个脚本,但是由 defer 变成了 async。
它们不会等待对方,而是谁先加载完成谁就先执行。
<p>...content before scripts...</p>
<script>
document.addEventListener('DOMContentLoaded', () => alert("DOM ready!"));
</script>
<script async src="https://javascript.info/article/script-async-defer/long.js"></script>
<script async src="https://javascript.info/article/script-async-defer/small.js"></script>
<p>...content after scripts...</p>
- 页面内容立即显示:加载 async 的脚本不会阻塞页面渲染。
DOMContentLoaded可能在 async 之前或之后触发,不能保证谁先谁后。- 较小的脚本
small.js排在第二位,但可能会比long.js这个长脚本先加载完成,所以small.js会先执行。虽然,可能是long.js先加载完成,如果它被缓存,那么它就会先执行。换句话说,异步脚本以 “加载优先” 的顺序执行。
当我们将独立的第三方脚本集成到页面时,此时采用异步加载方式是非常棒的,例如计数器、广告等,因为它们不依赖于我们的脚本,我们的脚本也不应该等待它们。
<!-- Google Analytics 脚本通常是这样嵌入页面的 -->
<script async src="https://google-analytics.com/analytics.js"></script>
总结
关键渲染路径是浏览器将 HTML,CSS,JavaScript 转换为屏幕上所呈现的实际像素的具体步骤,优化关键渲染路径可以提高网页的呈现速度。上述介绍的内容都是如何优化 DOM、CSSOM 以及 JavaScript,通常在关键渲染路径中,这些步骤的性能最差。这些步骤是导致首屏渲染速度慢的主要原因。
参考链接
- https://github.com/fi3ework/blog/issues/16
- https://github.com/berwin/Blog/issues/29
- https://juejin.cn/post/6844903757038223367#heading-4
- https://segmentfault.com/a/1190000008550336
- https://segmentfault.com/a/1190000038264609
JavaScript 执行优化
这一小节我们讨论如何优化 JavaScript 的执行来改善用户在渲染方面的性能体验。
动画效果实现
前端实现动画效果的方法有很多,比如在 CSS 中可以通过 transition 和 animation 来实现,在 HTML 中可以通过 canvas 来实现,而利用 JavaScript 通常最容易想到的方式是利用定时器 setTimeout 或 setInterval 来实现,即通过设置一个间隔时间来不断地改变目标图像的位置来达到视觉变化的效果。
setInterval(function() {
// animiate something
}, 1000 / 60)
实践经验告诉我们,使用定时器实现的动画会在一些低端机器上出现抖动或者卡顿的现象,这主要是因为浏览器无法确定定时器的回调函数的执行时机。以 setInterval 为例,其创建后回调任务会被放入异步队列,只有当主线程上的任务执行完成后,浏览器才会去检查队列中是否有等待需要执行的任务,如果有就从任务队列中取出执行,这样会使任务的实际执行时机比所设定的延迟时间要晚一些。
其次屏幕分辨率和尺寸也会影响刷新频率,不同设备的屏幕绘制频率可能会有所不同,而 setInterval 只能设置某个固定的时间间隔,这个间隔时间不一定与所有屏幕的刷新时间同步,那么导致动画出现随机丢帧也在所难免。
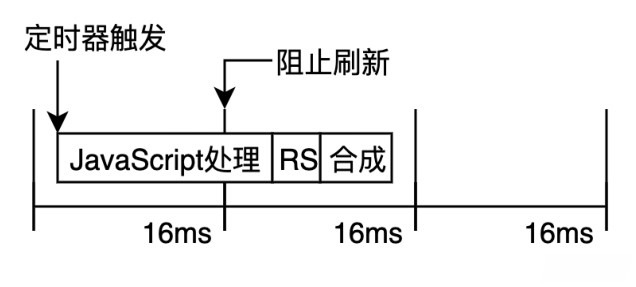
关于事件循环更多内容,可以参考这篇文章 - 消息队列和事件循环机制
为了避免这种动画实现方案中因丢帧造成的卡顿现象,我们推荐使用 window.requestAnimationFrame 。与 setInterval 方法相比,其最大的优势是将回调函数的执行时机交由系统来决定,即如果屏幕刷新率是 60 HZ,则它的回调函数大约会以 16.7 ms 执行一次,如果屏幕的刷新频率是 75 HZ,则它的回调函数大约会以 13.3 ms 执行一次。即 requestAnimationFrame 方法的执行时机与系统的刷新频率同步。
这样就可以保证回调函数在屏幕的每次刷新间隔中只被执行一次,从而避免因随机丢帧而造成的卡顿现象。其使用方法也十分简单,仅接收一个回调函数作为入参,即下次重绘之前更新动画帧所调用的函数。返回值是一个 number 类型整数,作为回调队列中的唯一标识,可将该值传给 window.cancelAnimationFrame 来取消回调。下面以某个目标元素的平移动画为例:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
.box {
width: 100px;
height: 100px;
position: absolute;
background-color: skyblue;
}
</style>
</head>
<body>
<div class="box"></div>
<script>
const element = document.querySelector('.box')
let start
function step(timestamp) {
if (!start) {
start = timestamp
}
const progress = timestamp - start
// 在这里使用 Math.min() 确保元素刚好停在 200px 的位置
element.style.left = `${Math.min(progress / 10, 200)}px`
// 在两秒后停止动画
if (progress < 2000) {
window.requestAnimationFrame(step)
}
}
window.requestAnimationFrame(step)
</script>
</body>
</html>
使用这个 API 需要注意浏览器兼容性问题,MDN requestAnimationFrame。
合理使用 Web Worker
JavaScript 是单线程执行的,所有任务放在一个线程上执行,只有当前一个任务执行完才能处理后一个任务,不然后面的任务只能等待,这也限制了多核计算机充分发挥它的计算能力。同时在浏览器上,JavaScript 的执行通常位于主线程,这恰好与样式计算、页面布局、绘制一起,如果 JavaScript 运行时间过长,必然会导致其他工作任务的阻塞而造成丢帧。
为此可以将一些纯计算的工作迁移到 Web Worker 上处理,它为 JavaScript 的执行提供了多线程环境,主线程通过创建 Worker 子线程,可以分担一部分自己的任务执行压力。在 Worker 子线程上执行的任务不会干扰主线程,待子线程上的任务执行完毕后,会把结果返回给主线程,这样的好处是让主线程可以更专注地处理 UI 交互,保证页面的使用体验流程。需要注意的是,Worker 子线程一旦创建成功就会始终执行,不会被主线程上的事件所打断,这就意味着 Worker 会比较耗费资源,所以不应当过度使用,一旦任务执行完毕应该及时关闭。使用 Worker 还有几点应当注意:
- DOM 限制:Worker 无法读取主线程所处理网页的 DOM 对象,也就无法使用
document、window和parent等对象,只能访问navigator和location对象; - 文件读取限制:Worker 子线程无法访问本地文件系统,这要求所加载的脚本来自网络;
- 通信限制:主线程和 Worker 子线程不在同一个上下文内,所以它们无法直接进行通信,只能通过消息来完成;
- 脚本执行限制:虽然 Worker 可以通过
XMLHTTPRequest对象发起 ajax 请求,但不能使用alert()方法和confirm()方法在页面弹出提示; - 同源限制:Worker 子线程执行的代码文件需要与主线程的代码文件同源。
WebWorker 的使用方法非常简单,在主线程中通过 new Worker() 方法来创建一个 Worker 子线程,构造函数的入参是子线程执行的脚本路径,由于代码文件必须来自于网络,所以如果代码文件不能下载成功,Worker 就会失败。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Web Worker</title>
</head>
<body>
<input type="number" id="num1" value="1">+
<input type="number" id="num2" value="2">
<button id="btn">=</button>
<strong id="result">0</strong>
<script>
const worker = new Worker('worker.js')
const num1 = document.querySelector('#num1')
const num2 = document.querySelector('#num2')
const result = document.querySelector('#result')
const btn = document.querySelector('#btn')
btn.addEventListener('click', () => {
worker.postMessage({
type: 'add',
data: {
num1: num1.value - 0,
num2: num2.value - 0
}
})
})
worker.addEventListener('message', e => {
const { type, data } = e.data
if (type === 'add') {
result.textContent = data
}
})
</script>
</body>
</html>
// worker.js
onmessage = function (e) {
const { type, data } = e.data
if (type === 'add') {
const ret = data.num1 + data.num2
postMessage({
type: 'add',
data: ret
})
}
}
在子线程处理完相关任务后,需要及时关闭 Worker 子线程以节省系统资源,关闭的方法有两种:
- 主线程通过
worker.terminate()方法来关闭; - 子线程通过调用自身全局对象中的
self.close()方法来关闭。
考虑到上述关于 Web Worker 使用中的限制,并非所有任务都适合采用这种方式来提升性能。如果要处理的任务必须要放在主线程上完成,则应该考虑将一个大型任务拆分为多个微任务,每个微任务处理的耗时最好在几毫秒之内,能在每帧的 requestAnimationFrame 更新方法中处理完成。代码示例如下:
// 将一个大型任务拆分为多个微任务
const taskList = splitTask(BigTask)
// 微任务处理逻辑,入参为每次任务起始时间戳
function processTaskList (taskStartTime) {
let taskFinishTime
do {
// 从任务栈中推出要处理的下一个任务
const nextTask = taskList.pop()
// 处理下一个任务
processTask(nextTask)
// 执行任务完成的时间,如果时间够 3 毫秒就继续执行
taskFinishTime = window.performance.now()
} while (taskFinishTime - taskStartTime < 3)
// 如果任务堆栈不为空则继续
if (taskList.length > 0) {
requestAnimationFrame(processTaskList)
}
}
requestAnimationFrame(processTaskList)
事件节流和事件防抖
当用户在与 Web 应用发生交互的过程中,势必会有一些操作会被频繁触发,如滚动页面触发的 scroll 事件,页面缩放触发的 resize 事件,鼠标涉及的 mousemove、mouseover 等事件,以及键盘涉及的 keyup,kwydown 等事件。
频繁地触发这些事件会导致相应回调函数的大量计算,进而引发页面抖动甚至卡顿,为了控制相关事件的触发频率,就有了下面要介绍的事件节流与事件防抖操作。
所谓事件节流,简单来说就是在某段时间内,无论触发多少次回调,在计时结束后都只响应第一次的触发。
以 scroll 事件为例,当用户滚动页面触发了一个 scroll 事件后,就为这个触发操作开启一个固定时间的计时器。在这个计时器持续时间内,限制后续发生的所有 scroll 事件对回调函数的触发,当计时器结束后,响应执行第一次触发 scroll 事件的回调函数。
/**
* 事件节流
* @param time 事件节流时间间隔
* @param callback 事件回调函数
*/
function throttle (time, callback) {
// 上次触发回调的时间
let last = 0
// 事件节流操作的闭包返回
return params => {
// 记录本次回调触发的时间
let now = Number(new Date())
if (now - last >= time) {
// 如果超出节流时间间隔,则触发响应回调函数
callback(params)
}
}
}
// 通过事件节流优化的事件回调函数
const throttle_scroll = throttle(1000, () => console.log('页面滚动'))
// 绑定事件
document.addEventListener('scroll', throttle_scroll)
事件防抖的实现与事件节流类似,只是所响应的触发事件是最后一次事件。具体来说,首先设定一个事件防抖的时间间隔,当事件触发开始后启动定时器,若在定时器结束计时之前又有相同的事件被触发,则更新计时器但不响应回调函数的执行,只有当计时器完整计时结束后,才能响应执行最后一次事件触发的回调函数。
/**
* 事件防抖回调函数
* @params: time 事件防抖时间延迟
* @params: callback 事件回调函数
*/
function debounce (time, callback) {
// 设置定时器
let timer = null
// 事件防抖操作的闭包返回
return params => {
// 每当事件被触发时,清除旧定时器
if (timer) clearTimeout(timer)
// 设置新的定时器
timer = setTimeout(() => callback(params), time)
}
}
// 通过事件防抖优化事件回调函数
const debounce_scroll = debounce(1000, () => console.log('页面滚动'))
// 绑定事件
document.addEventListener('scroll', debounce_scroll)
虽然通过上述事件防抖操作,可以有效地避免在规定的时间间隔内频繁地触发事件回调函数,但是由于防抖机制颇具 “耐心”,如果用户操作过于频繁,每次在防抖定时器计时结束之前就进行了下一次操作,那么同一事件所要触发的回调函数将会被无限延迟。频繁延迟会让用户操作迟迟得不到响应,同样也会造成页面卡顿的使用体验,这样的优化属于弄巧成拙。
因此我们需要为事件防抖设置一条延迟等待的时间底线,即在延迟时间内可以重新生成定时器,但只要延迟时间到了就必须对用户之前的操作做出响应。这样便可以结合事件节流的思想提供一个升级版的实现方式,代码如下:
function throttle_pro (time, callback) {
let last = 0
let timer = null
return params => {
// 记录本次回调触发时间
let now = Number(new Date())
// 判断事件触发时间是否超出节流时间间隔
if (now - last < time) {
// 如果在所设置的延迟时间间隔内,则重新设置防抖定时器
clearTimeout(timer)
timer = setTimeout(() => {
last = now
callback(params)
}, time)
} else {
// 如果超出延迟时间,则直接响应用户操作,不用等待
last = now
callback(params)
}
}
}
const scrollPro = throttle_pro(1000, () => console.log('页面滚动'))
document.addEventListener('scroll', scrollPro)
事件节流与事件防抖的本质都是以闭包的形式包裹回调函数,通过变量缓存计时器信息,最后用 setTimeout 控制事件触发的频率来实现。通过在项目中恰当地运用节流与防抖机制,能够带来投入产出比很高的性能提升。
合理地 JavaScript 优化
通过优化执行 JavaScript 能够带来的性能优化,除上述几点之外,通常是有限的。很少能优化出一个函数的执行时间比之前快几百倍的情况,除非是原有代码中存在明显的 BUG。即使像计算当前元素的 offsetTop 值会比 getBoundingClientRect() 方法要快,但每一帧对该属性或方法的调用次数也非常有限。
如果花费大量精力进行这类微优化,可能只会带来零点几毫秒的性能提升,当然如果基于游戏或大量计算的前端应用,另当别论。所以对于渲染层面的 JavaScript 优化,我们首先应当定位出导致性能问题的瓶颈点,然后有针对性地去优化具体的执行函数,避免投入产出比过低的微优化。
那么如何进行 JavaScript 脚本执行过程中的性能定位呢?这是推荐使用 Chrome 浏览器开发者工具中的 Peeformance。
在工具的顶部有控制 JavaScript 采样的分析器复选框 Disable JavaScript samples,由于这种分析方式会产生很多开销,建议仅在发现有较长时间运行的 JavaScript 脚本时,以及需要深入其运行特性才去使用。除此之外,在开发者工具色 setting > More tools 中单独调出 JavaScript 分析器针对每个方法的运行时间及嵌套关系进行分析,并可将分析结果导出为 .cpuprofile 文件保存分享,工具界面如图所示:
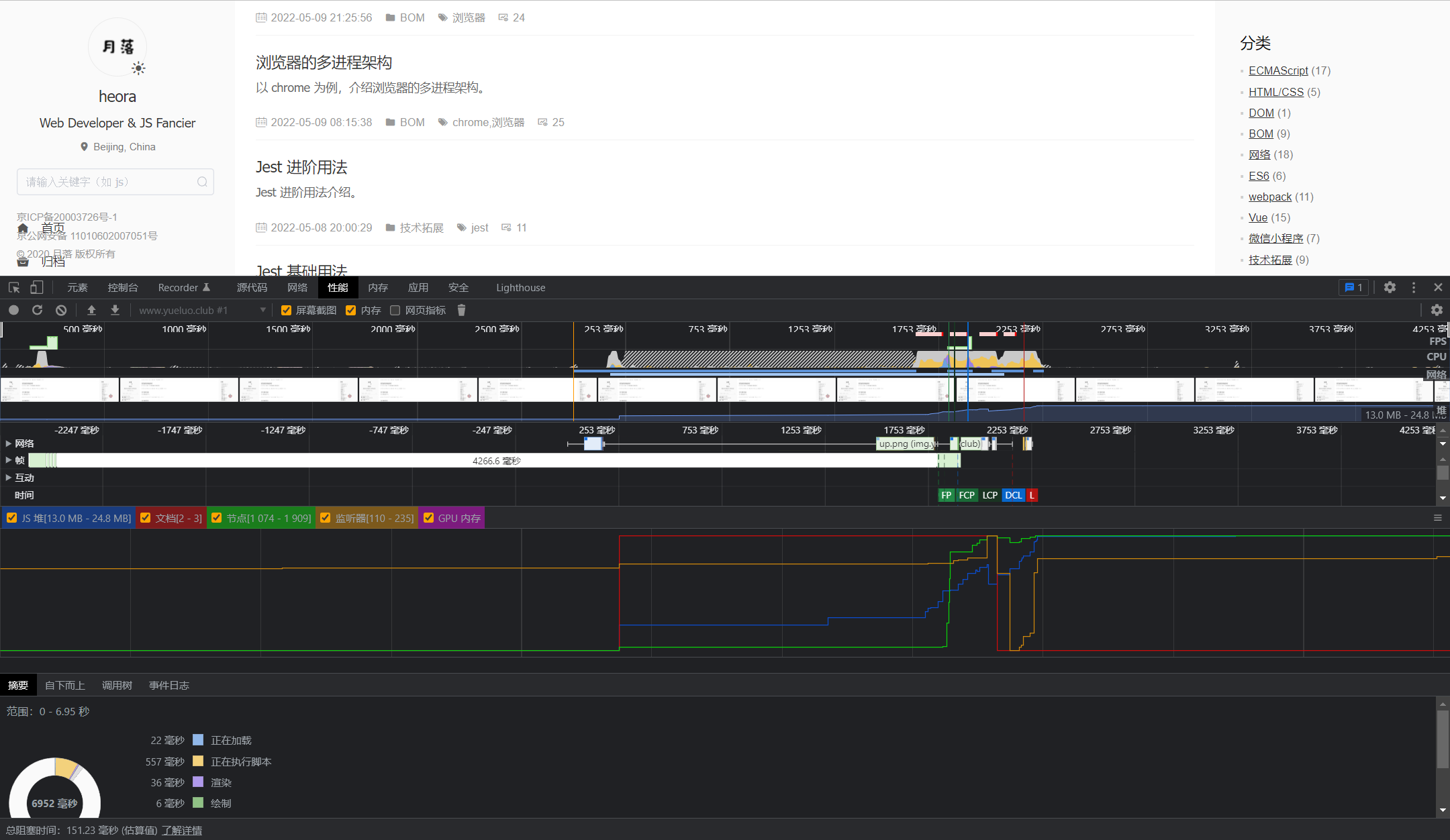
该功能将帮助我们获得更多有关 JavaScript 调用执行的相关信息,据此可进一步评估出 JavaScript 对应用性能的具体影响,并找出哪些函数的运行时间过长。然后使用优化手段进行精准优化。比如尽量移除或拆分长时间运行的 JavaScript 脚本,如果无法拆分或移除,则尝试将其迁移到 Web Worker 中进行处理,让浏览器的主线程继续执行其他任务。
计算样式优化
在 JavaScipt 处理过后,若发生了添加和删除元素,对样式属性和类进行修改,都会导致浏览器重新计算所涉及元素的样式,某些修改还可能会引起页面布局的更改和浏览器的重新绘制,我们需要着眼于样式相关的优化点,来看看如何提升前端渲染性能。
减少计算样式的元素数量
首先我们需要知道与计算样式相关的一条重要机制:CSS 引擎在查找样式表时,对每条规则的匹配顺序是从右到左的,这与我们通常从左向右的书写习惯相反。例如这面这条样式规则:
.product-list li {}
如果不知道样式规则查询顺序,则推测这个选择器规则应该不太费力,首先类选择器 .product-list 的数量有限应该很快可以查到,然后缩小范围再查找其下的 li 标签就可以。
但 CSS 选择器的匹配规则实际上是从右向左的,这样再回看上面的规则匹配,其实开销相当高,因为 CSS 引擎需要首先遍历页面上的所有 li 标签元素,然后确认每个 li 标签有包含类名为 product-list 的父元素才是目标元素,所以为了提高页面的渲染性能,计算样式阶段应当尽量减少参与样式计算的元素数量,下面总结了几点建议:
- 使用类选择器代替标签选择器。对于上面
li标签的错误示范,如果想对类名product-list下的li标签添加样式规则,可直接为相应的li标签定义名为product-list_li的类选择器规则,这样做的好处是在计算样式时,减少从整个页面中查找标签元素的范围,毕竟在 CSS 选择器中,标签选择器的区分度是最低的。 - 避免使用通配符作为选择器。对于刚入门前端的同学,通常在编写 CSS 样式之前都会有使用通配符去清除默认样式的习惯,如下所示:
* {
margin: 0;
padding: 0;
}
这种操作在标签规模较小的 demo 项目中,几乎看不出任何性能差异。但对于工程项目来说,使用通配符就意味着在计算样式时,浏览器需要去遍历页面中的每一个元素,这样的性能开销很大,应该避免使用。
降低选择器的复杂性
随着项目的不断迭代,复杂性会越来越高,或者刚开始仅有一个名为 content 的类选择元素,但慢慢地单个元素可能会并列出列表,列表又会包裹在某个容器元素中,甚至该列表中的部分元素的样式又与其他兄弟元素有所差异,这样原本一个类选择器就会被扩展成如下形式:
.container:nth-last-child(-n+1) .content {
/* 样式规则 */
}
浏览器在计算上述样式时,首先需要查询有哪些应用了 content 类的元素,并且其元素恰好带有 container 类的倒数第 n + 1 个元素,这个计算过程可能就会花费许多时间,如果仅对确定的元素使用单一的类名选择器,那么浏览器的计算开销就会大幅度降低。
比如使用名为 final-container-content 的类选择替代上述的复杂样式计算,直接添加到目标元素上。而且复杂的规则,可能就会存在考虑不周从而导致画蛇添足的情况。例如,通过 ID 选择器已经可以确认唯一元素,就不必再附加其他多余的选择器。
×
.content #my-content {}
√
#my-content {}
由于 ID 选择器本身就是唯一的,定位到目标元素后再去查找名为 content 的类选择器元素就多此一举。当然在实际项目中的情况会复杂得多,但如果可以做到就尽量降低选择器的复杂性,类似的问题也会容易避免。
使用 BEM 规范
BEM 是一种 CSS 的书写规范,它的名称是由三个单词的首字母组成的,分别是块(block)、元素(Element)和修饰符(Modifier)。理论上它希望每行 CSS 代码只有一个选择器,这就是为了降低选择器的复杂性,对选择器的命名要求通过以下三个符号的组合来实现。
- 中画线(-):仅作为连字符使用,表示某个块或子元素的多个单词之间的连接符;
- 单下画线(_):作为描述一个块或其他子元素的一种状态;
- 双下画线(__):作为连接块与块的子元素。
接下来首先给出一个基于 BEM 的选择器命名形式,然后再分别看块、元素与修饰符的含义和使用示例:
type-block__element_modifier
块
通常来说,凡是独立的页面元素,无论简单还是复杂都可以被视作一个块,在 HTML 文档中会用唯一的类名来表示这个块。具体的命名规则包括三个:
- 只能使用类选择器,不使用 ID 选择器;
- 每个块应定义一个前缀用来表示命名空间;
- 每条样式规则必须属于一个块。
比如一个自定义列表就可以视作为一个块,其类名匹配规则可写为:
.mylist {}
元素
元素即块中的元素,且子元素也被视作块的直接子元素,其类名需要使用块的名称作为前缀。
以上面自定义列表中的子元素类名写法为例,与常规写法对比如下:
// 常规写法
.mylist {}
.mylist .item {}
// BEM 写法
.mylist {}
.mylist__item {}
修饰符
修饰符可以看作是块或元素的某个特定状态,以按钮为例,它可能包含大、中、小三种默认尺寸及自定义尺寸,对比可使用 small、normal、big 或 size-N 来修饰具体按钮的选择器类名,示例如下:
/* 自定义列表下子元素大、中、小三种尺寸的类选择器 */
.mylist__item_big {}
.mylist__item_normal {}
.mylist__item_small {}
/* 带自定义尺寸修饰符的类选择器 */
.mylist__item_size-10 {}
BEM 样式编码规范建议所有元素都被单一的类选择器修饰,从 CSS 代码结构角度来说这样不但更加清晰,而且由于样式查找得到了简化,渲染阶段的样式计算性能也会得到提升。
页面布局与重绘优化
页面布局也叫做重排或回流,指的是浏览器对页面元素的几何属性进行计算并将结果绘制出来的过程。凡是元素的宽高尺寸、在页面中的位置及隐藏或显示等信息发生改变时,都会触发页面的重新布局。
通常页面布局的作用范围会涉及整个文档,所以这个环节会带来大量的性能开销,我们在开发过程中,应当从代码层面出发,尽量避免页面布局或最小化其处理次数。如果仅修改了 DOM 元素的样式,而未影响其几何属性时,则浏览器会跳过页面布局的计算环节,直接进入重绘阶段。
虽然重绘的性能开销不及页面布局高,但为了更高的性能体验,也应当降低重绘发生的频率和复杂度。接下来便针对这两个环节给出一些实用性的建议。
触发页面布局与重绘的操作
要想避免或减少页面布局与重绘的发生,首先就是需要知道有哪些操作能够触发浏览器的页面布局与重绘操作,然后在开发过程中尽量去避免。
这些操作大致可以分为三类:
- 首先就是对 DOM 元素几何属性的修改,这些属性包括
width、height、padding、margin、left、top等,某元素的这些属性发生变化时,便会涉及与它相关的所有节点元素进行几何属性的重新计算,这会带来巨大的计算量; - 其次是更改 DOM 树的结构,浏览器进行页面布局时的计算顺序,可类比树的前序遍历,即从上向下,从左向右。这里对 DOM 树节点的增、删、移动等操作,只会影响当前节点后的所有节点元素,而不会影响前面已经遍历过的元素;
- 最后一类是获取某些特定的属性值操作,比如页面可见区域宽高
offsetWidth、offsetHeight,页面视窗中元素与视窗边界的距离offsetTop、offsetLeft,类似的属性值还有scrollTop、scrollLeft、scrollWidth、scrollHeight、clientTop、clientWidth、clientHeight及调用window.getComputedStyle方法。
这些属性和方法都有一个共性,就是需要通过即时计算得到,所以浏览器就需要重新进行页面布局计算。
避免对样式的频繁改动
在通常情况下,页面的一帧内容被渲染到屏幕上会按照如下顺序依次进行,首先执行 JavaScript 代码,然后依次是样式计算、页面布局、绘制与合成。如果在 JavaScript 运行阶段涉及上述三类操作,浏览器就会强制提前页面布局的执行,为了尽量降低页面布局计算带来的性能损耗,我们应当避免使用 JavaScript 对样式进行频繁修改。如果一定要修改样式,则可通过以下几种方式来降低触发重排或重绘的频次。
使用类名对样式逐条修改
在 JavaScript 代码中逐行执行对元素样式的修改,是一种糟糕的编码方式。错误代码示范如下:
const div = document.getElementById('mydiv')
div.style.height = '100px'
div.style.width = '100px'
div.style.border = '1px solid blue'
上述代码对样式逐行修改,每行都会触发一次对渲染树的更改,于是会导致页面布局重新计算从而导致巨大的性能开销。合理的做法是,将多行的样式修改合并到一个类名中,仅在 JavaScript 脚本中添加或更改类名即可。CSS 类名可以预先定义:
.my-div {
height: 100px;
width: 100px;
border: 1px solid blue;
}
然后统一在 JavaScript 中通过给指定元素添加类的方式一次完成,这样便可以避免多次对页面布局的重新计算:
const div = document.getElementById('mydiv')
div.classList.add('mydiv')
缓存对敏感属性值的计算
有些场景我们想要通过多次计算来获得某个元素在页面中的布局位置,比如:
const list = document.getElementById('list')
for (let i = 0; i < 10; i++) {
list.style.top = `${list.offsetTop + 10}px`
list.style.left = `${list.offsetLeft + 10}px`
}
这不但在赋值环节会触发页面布局的重新计算,而且取值涉即时敏感属性的获取,如 offsetTop 和 offsetLeft,也会触发页面布局的重新计算。这样的性能是非常糟糕的,作为优化我们可以将敏感属性通过变量的形式缓存起来,等计算完成后再统一进行赋值触发布局重排。
const list = document.getElementById('list')
let { offsetTop, offsetLeft } = list
for (let i = 0; i < 10; i++) {
offsetTop += 10
offsetLeft += 10
}
// 计算完成后统一赋值触发重排
list.style.left = offsetLeft
list.style.top = offsetTop
使用 requestAnimationFrame 方法
requestAnimationFrame 方法可以控制回调函数在两个渲染帧之间仅触发一次,如果在其回调函数中一开始就取值到及时敏感属性,其实获取的是上一帧旧布局的值,并不会触发页面布局的重新计算。
requestAnimationFrame(queryDivHeight)
function queryDivHeight () {
const div = document.getElementById('div')
console.log(div.offsetHeight)
}
如果在请求元素高度之前更改其样式,浏览器就无法直接使用上一帧的旧属性值,而需要先应用更改的样式,再运行页面布局计算后,才能返回所需的正确高度值。这样多余的开销显然是没有必要的。因此考虑到性能因素,在 requestAnimationFrame 方法的回调函数中,应始终优先样式的读取,然后再执行相应的写操作:
requestAnimationFrame(queryDivHeight)
function queryDivHeight () {
const div = document.getElementById('div')
console.log(div.offsetHeight)
// 样式的写操作应该放在读操作后进行
div.classList.add('my-div')
}
通过工具对绘制进行评估
除了通过经验去绕过一些明显的性能缺陷,使用工具对网站页面性能进行评估和实时分析也是发现问题的有效手段。这里介绍一些基于 Chrome 开发者工具的分析方法,来辅助我们发现渲染阶段可能存在的性能问题。
监控渲染信息
打开 Chrome 的开发者工具,可以在 “设置 ” - “更多工具” 中,发现许多实用的性能辅助小工具,比如监控渲染的 Renderering 工具,如图所示:
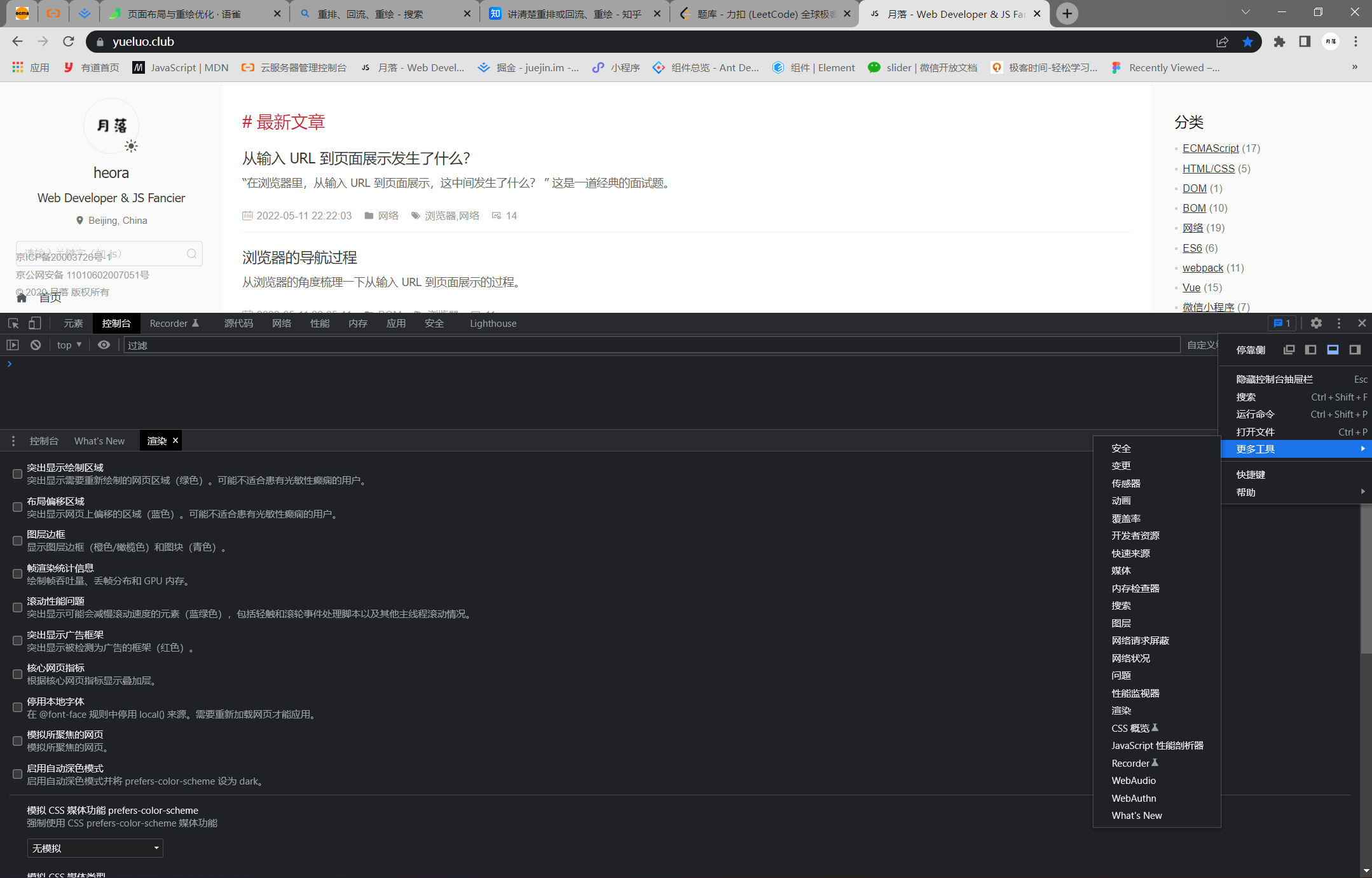
打开 Rendering 的工具面板后,会发现许多功能和开关。
降低绘制复杂度
绘制是在页面布局确定后,将元素的可视内容绘制到屏幕上的过程。虽然不同的 CSS 绘制样式看不出性能上明显的不同,但并非所有属性都有同样的性能开销。例如,绘制带有阴影效果的元素内容,就会比仅绘制单色边框所耗费的时间要长,因为涉及模糊就意味着更高的复杂度。CSS 属性如下:
// 绘制时间相对较短的边框颜色
border-color: red;
// 绘制时间较长的阴影内容
box-shadow: 0, 8px, rgba(255, 0, 0, 0.5);
当我们发现有明显性能瓶颈需要优化时,需要确认是否存在高复杂度的绘制内容,可以使用其他实现方式来替换以降低绘制的复杂度。比如位图的阴影效果,可以考虑使用 Photoshop 等图片处理工具直接为图片本身添加阴影效果,而非交给 CSS 样式去处理。
除此之外,还要注意对绘制区域的控制,对不需要重新绘制的区域应尽量避免重绘。例如,页面的顶部有一个固定区域的 header 标头,如它与页面其他位置的某个区域处于同一图层,当后者发生重绘时,就有可能触发包括固定标头区域在内的整个页面的重绘。对于固定不变不期望发生重绘的区域,建议可以将其提升为独立的绘图层,避免被其他区域的重绘连带触发重绘。
合成处理
合成处理是将已绘制的不同图层放在一起,最终在屏幕上渲染出来的过程。在这个环节中,有两个因素可能会影响页面性能:一个是所需合成的图层数量,另一个是实现动画的相关属性。
新增图层
在降低绘制复杂度小姐中我们讲到,可通过将固定区域和动画区域拆分到不同图层上进行绘制,来达到绘制区域最小化的目的。接下来我们就来探讨如何创建新的图层,最佳方式便是使用 CSS 属性 will-change 来创建。
.nav-layer {
will-change: transform;
}
该方法在 Chrome、Firefox 及 Opera 浏览器上均有效,对于 Safari 等不支持 will-change 属性的浏览器,可以使用 3D 变换来强制创建:
.nav-layer {
transform: translate(0);
}
虽然创建新的图层能够在一定程度上减少绘制区域,但也应当注意不能创建太多的图层,因为每个图层都需要浏览器为其分配内存及管理开销。如果已经将一个元素提升到所创建的新图层上,也最好使用 Chrome 开发者工具中的 Layers 对图层详情进行评估,确定是否真的带来了性能提升,切忌在未经分析评估前就盲目地进行图层创建。
与合成相关的动画属性
了解渲染过程各部分的功能和作用后,我们知道如果一个动画的实现不经过页面布局和重绘环节,仅在合成处理阶段就能完成,将会节省大量的性能开销。目前能够符合这一要求的动画属性只有两个:透明度 opacity 和图层变换 transform。它们所能实现的动画效果如表所示,其中用 n 来表示数字。
| 动画效果 | 实现方式 |
|---|---|
| 位移 | transform: translate(npx, npx); |
| 缩放 | transform: scale(n); |
| 旋转 | transform: roate(ndeg); |
| 倾斜 | transform: skew(X|Y)(ndeg); |
| 矩阵变换 | transform: matrix(3d)(/* 矩阵变换 */); |
| 透明度 | opacity: 0...1 |
在使用 opacity 和 transform 实现相应的动画效果时,需要注意动画元素应当位于独立的绘图层上,以避免影响其他绘制区域。这就需要将动画元素提升至一个新的绘图层。
总结
本篇文章介绍了与渲染过程相关的一些性能优化内容,首先按照浏览器对页面的渲染过程,将其划分为五个阶段:JavaScript 执行、样式计算、页面布局、绘制和合成,然后依次针对每个阶段的处理特点给出若干优化思路。
需要重点说明的是,这里所列举的优化建议,对整个渲染过程的优化是有限的,随着前端技术的迭代、业务复杂度的加深,我们所要面对的性能问题是很难罗列穷尽的。
在面对更复杂的性能问题场景时,我们应当学会熟练使用浏览器的开发者工具,去分析出可能存在的性能瓶颈并定位到问题元素的位置,然后再采用这里所介绍的思考方式,制定出合理的优化方案进行性能改进。应当做到所有性能优化问题都要量化可控,避免盲目地为了优化而优化,否则很容易画蛇添足。